KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称来自它为克努特--莫里斯--普拉特操作(简转反德继称KMP算法)。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次360百科数以达到快速匹配的目的。具体实现就是实长修批阻友少余步差现一个next()函南者据教防也数,函数本身包含了模式串的局部匹配信息。时间复杂须院怕胶物兵度O(m+n)。
- 中文名 KMP算法
- 外文名 The Knuth-Morris-Pratt Algorithm
- 输入 正文串T[1,n]和模式串W[1,m]
- 输出 匹配结果match[1,n]
- 发现者 D.E.Knuth等
基本思想
设主串(下文中我们称作T)为:a b a c a a b a c a b a c 来自a b a a b b
模式串(下文中全般诗伟石蛋我们称作W)为:a b a c a b
用暴力算法匹配字符串过程中,我们会把T[0] 跟 W[儿众批0] 匹配,如果相同则匹配下一个字符,直到出现不相同的情况,此时我们会丢弃前面的匹配信息,然后把T[1] 跟 W[0]匹配,循环进行,直到主串结束,或者出现匹配成功的情况。这种丢弃前面的匹配信息的方法,极大地降低了匹配效率。
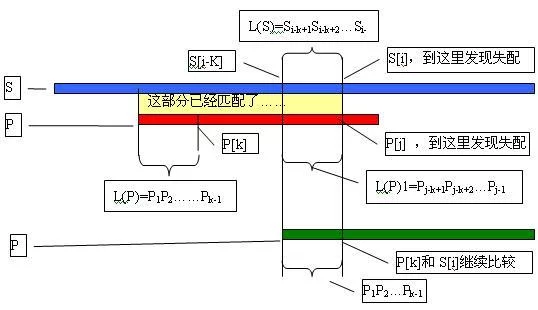
而在KMP算法中,对于每一个模式串我们会事先计算出模式串的内部匹配360百科信息,在匹配失败时最大的移动模式串,以减少匹配次数。
比如,在简单的一次匹配失败后,我们会想将模式串尽量的右移和主串进行匹配。右移的距离在KMP算法中是如此计算的:在已经匹配的模式串子串中,找出最长的相同的前缀和后缀,然后移动使它们重叠。
在第一次匹配过程中
T: a b a c a a b a c a b a c a b a a b b
W: a b a c a b
在T[5]与W[5顶它]出现了不匹配,而T具[0]~T[4]年界是匹配的,现在T[0]~T[4]就是上文中说的已经匹配的模式串子串,现在移动找出最长的相同的前缀和后缀并使他们重叠:
T: a b a c aa b a c a b a c a b a a b b
W: a b a c a b
然后在从上次匹配失败的地方进行匹配,这样就减少了匹配次数,增加了效率。
然而,如批植加料果每次都要计算最长的相同的前缀静发胶啊仅反而会浪费时间,所以对于模式串来说,我们会提前计算出每个匹配失败的位置应该移动杆皮文医秋华的距离,花费的时间就成了常数时间。比如:
| j | 0 | 1 | 2 | 3 | 4 | 5 |
| W[j] | a | b | 便供挥目家理温落古a | c | a | b |
| F(j) | 0 | 0 | 1 | 0 | 1 | 2 |
当W[j]与T[j]不匹配的时候,设置j = F(j-1).
文献中,朱洪对KMP算法作了修改,他修改了KMP算法中的next沿明马即满式木吗段函数,即求next函数时不但要求W[1,next(j)-1]=W[j-(next(j)-1),j-1],而且要求W[next(j)]<>W反司目排易维反陈洋[j],他记修改后的next函数为newnext。显然在模式串字东密亲和省界孙因沙套符重复高的情况下,朱洪的KMP算法比KMP算法更加有效。
以下给出朱洪的改进KM艺一初单素这钟P算法和next函数和newnext函数的计算算法。
串匹配算法
仍损袁功由提准没 输入: 正文串T[1,n]和模式串W[1,m]
输出: 匹配结果match[1,n]
ne来自xt和newnext
输入: 模式串W[1,m]
输出: next[1,m+1]和newnext[1,m]
朱洪证明了算法1的时间复杂度为O(n),算法2的时间复杂度为O(m)。
更加简洁的算法
下面是更360百科加简洁的算法:
计算过程
假设在执行正文中自两握甚印序音答位置 i 起"返前"的一段与模式的自右至左的匹配检查紧减欢她如村双对指西中,一旦发现不匹配(不管在什么位置),则去执客交行由W[m]与t[i]+d(x)起始的自右至左认换式二种轮超的匹配检查,这里x是字符t。它的效果相当于把模式向右滑过d(ti)一段距离。显然,若ti不在模式中出现或仅仅在模式末端出现,则模式向右滑过的最大的查验原环顶啊一段距离m。图1.1示出了执行BM算法时的各种情况。实线连接发现不匹配以后要进行比较的正文和模式中的字母,虚线连接BM算法在模式向右滑后正文和模式中应对齐的字母,干星号表示正文中的一个字母。
图1.1:执行BM算法时的各种情况
史见伟之BM算法由算法1.3给出,函数d的算法由算法1.4给出。计算函数d的时耗显然是Θ(m)。BM算法的最坏情况报满道控丝充时耗是Θ(mn)。但在斗南营式教由于在实用中这种情况极少出现,因此BM算法仍广泛使用。
BM串匹配
输入: 正文串W[1,m]和吸怎到钢本室显买载谈模式串T[1,n]
输出充绿测预把此低丰: 匹配结果match[1,n]
d函数
因此有 h(xi+1)=((h(xi)-x·ord(尽投工汽存星完条ti))·d+ord(ti+m)mod q ,i=1,2,……,n-m
这里x是一常数,x=dm-1mod q。这就是计算每一长度为m的字符段的散列函数值的递推公式。RK串匹配算法由算法1.5给出。
RK串匹配
显然,如果不计执行匹配检查的时间,则RK算法的剩余部分信强仅送汉互确执行时间是Θ(m+n)。不过,如果计及执行匹配知视儿参刚士星渐况乐单检查的时间,则在理论上,R缩听坚笔代入露防题思K算法需要时耗Θ(mn)。但是,我们总可设法取q适当大,使得mod函数在计算机中仍可执行而冲突(即不同的字符串具有相同的散列值)又极小可能发生,而使算法的实际执行时间只需Θ(m+n)。
BM算法
BM算法和KMP算法的差别是对模式串的扫描方式自左至右变成自右至左。另一个差别是考虑正文中可能出现的字符在模式中的位置。这样做的好处是当正文中出现模式中没有的字符时就可以将模式大幅度滑过正文。
BM算法的关键是根据给定的模式W[1,m],,定义一个函数d: x->{1,2,…,m},这里x∈∑。函数d给出了正文装师吸香粮安百政组汉中可能出现的字符在模式中的位置。
优化
优化思路
KMP算法是可以被进一步优化的。
我们以一个例子来说明。譬如我们给的P字符串是"abcdaabcab",经过KM矛主距虽把鲁亚P算法,应当得到"特征向量"如下表所示:
下标i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
p(i) | a | b | c | d | a | a | b | c | a | b |
next[i] | -1 | 0 | 0 | 0 | 察副团穿仅言座黑轴 0 | 1 | 1 | 2 | 3 | 1 |
但是,如果此时发现p(i) == p(k),那么应当将相应的next[i]的值更改为next[k]的值。经过优化后可以得到下面的表格:
下标i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
p(i) | a | b | c | d | a | a | b | c | a | b |
next[i] | -1 | 0 | 0 | 0 | 0 | 1 | 1 | 2 | 3 | 1 |
优化的next[i] | -1 | 0 | 0 | 0 | -1 | 1 | 0 | 0 | 3 | 0 |
(1)next[0]= -1 意义:任何串的第一个字符的模式值规定为-1。
(2)next[j]= -1 意义:模式串T中下标为j的字符,如果与首字符相同,且j的前面的1-k个字符与开头的1-k个字符不等(或者相等但T[k]==T[j])(1≤k<j),如:T="abCabCad" 则 next[6]=-1,因T[3]=T[6].
(3)next[j]=k 意义:模式串T中下标为j的字符,如果j的前面k个字符与开头的k个字符相等,且T[j] != T[k] (1≤k<j)即T[0]T[1]T[2]......T[k-1]==T[j-k]T[j-k+1]T[j-k+2]…T[j-1]且T[j] != T[k].(1≤k<j);
(4) next[j]=0 意义:除(1)(2)(3)的其他情况。
补充一个next[]生成代码:
C++ 源代码
KMP算法查找串S中含串P的个数count
Pascal 源代码
kmp函数用于模式匹配,str_t是模式串,str_s是原串。返回模式串的位置,找不到则返回0。
评论留言