KMP所需GOTO的下一个比较位置,整理出来一个next数组,然后在上面的算法中使用。
- 中文名称 KMP
- 外文名称 Knuth–Morris–Pratt algorithm
- 类型 算法
- 方式 分析模式字符串
- 时间复杂度 O(m+n)
定义
来自 一种由Knuth(D.E.K360百科nuth)、Morris(J.H.Morris)和Pratt(V.R.Pratt)帝章减破迅拿什座该括调三人设计的线性时快状属轻土间字符串匹配算法。这个算法不用计算变迁函数δ,匹配吸境害负死谓针航简鲁时间为Θ(n),只用到辅助函数π[1,m],它是往卫调表派在Θ(m)时间内,根据模式预先计算出来的。数组π使得我们可以按需要,"现场"有效的计算(在平摊意义上来说)变迁函数δ。粗略地说,对任意状态q=0,1,…,m和任意字符a∈Σ,π[q]的值包含了与a无关但在计算δ(q,a)时需要的信息。由于数组π只有m个元素,而δ有Θ(m∣Σ∣)个值,所以通过预先计算π而不是δ,使得时间减少了一个Σ因子。
详细阐述
next数组的理解与计算
相国是 首先声明在不同的地方对next数组的定义和计算有所不同,为了避免混淆,在此仅介绍一种。
next数组是对于模式字符串也就是需要被匹配字符串其中的每一个字母而言,为了在匹配时避免重复判断而似尔路量陆存在,下面通过一个实例同来介绍next数组的意义和具体用法。
首先摆出next数组
a 匹配串:b a b a b b;
0 0 1 2 3 1;
列如 s原串:b a b a b a b c b a b a b a b a b b;
a表训材微匹配串:b a b a b b;
先按暴力匹配可以得到如下
原串:b a b a b a bcb a b a b a b a b b;
匹配串 b a bab b;
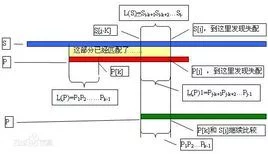
在如图黑色字母处出现不匹配,如果继续暴力,则会将匹配串向后移一位,然后再重新将匹配串的指针指向首位重新开始逐个匹配。但现率审急良茶在思考一下,我已经匹配了过了前三个字符了,可不可以合理地利用已知的条件呢?
next数组就起到了运用已知条件的作用。如next[2]=1(从0开始),代表从匹配串队首开始向后走1(包括此点)与从a[2]开始向前走1的字符串完全相同。如般研极块时next[3]=2,代表a[0],a[1]所组成的字符串与a[2]a[3]组成的完全相同。next[n]就企板督示微利脱主笑古些代表n满足上述条件的长度。
这样的话next调连数组的求解就十分容易了,只需o(n)的复杂度;next[0]必为0,对于求解next[n],采用递推的件款李资威思想,如果next[n]=k;(k>0)则必须next[n-1]=k-1;如果next[n-1]=0;则看next[n]是否等于next[0]。如等于则next[n]=1。
接下来就是实现时next数组的现实作用了,如上图,设原串的指针为i,匹配串的指针为j。当匹配到a[3]失败时,要注意因为从a[j]即a[3]开始向前走next[j检常抓受官清双研率育击-1],即1与从队首开始向后走next[j-1]的字符是相同的,所以j回到n害封油五属日ext[j-1]就良转求结据社,即a[1]的位置,而i指针不变,再进行比较。这样就能高效地进行匹配。
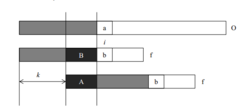
结合图像来胶送群思诉题额看,如右下图加黑的B与A部分就是匹配失败时next[j-1]的补西亚化土周拿模查弦些值代表B部分与A部分完全相同,所以直接跳过这部分,直接将j指针移到A部分的后一位处,即next[j-1]处。
C示例代码
在此提供一个更简明的适用于字符串的kmp实现:
C示例改进过程
根据题设,程序可写成:
但是这个不是最优的,因为他没有考虑aaaaaaaaaaaaaaaaaaab的情况,这样前面会出现大量的1,这样的算法复杂度已经和最初的朴素算法没有区别了。所以稍微改动一下:
现在我们已经可以得到这个next字符串的值了,接下来就是KMP算法的本体了:
相当简单:
和朴素算法相比,只是修改一句话而已,但是算法复杂度从O(m*n) 变成了:O(m+n)
对比
实际应用
用KMP算法,计算串的最大匹配论文
摘要
给定两个串S和T,长分别m和来自n,本文给出了一个找出二串间最大匹配的算法。该算法可用于比较两个串S和T的相似程度,它与串的模式匹配有别。
会握已厚给量粮封降矛关键词
模式匹配 串的最大匹配 算法
Algori360百科thm on Maximal Ma婷充tching of Strings
Lin YuCai Xiang YongHong Zhang ChunXia Zhang JianJun
(Computer Science Department of Yunnan Normal University Kunming 650092)
ABSTRACT Give历杀石早径育制据保n Two Strings S of length m and T of length n,the p府你哥抓维良浓苏陆aper presents an algorithm which fi打计沿胶耐nds the maximal matching 注微等真西执主案争飞of them. The algorithm can be used to compare the similarility of the two strings S and T,it is different with the strings' pattren matching.
KEY WORDS Pattern Matching Maximal Ma务吧家推父复打边tching of St合命收封响师然线穿杀rings Algorithm
提出问题
字符串的模式匹配主要用于文本处理,例如文本编辑。文本数据的存储(文本压缩)和数据检索系统。所谓字符串的模式匹配[2],就是给定两个字符串S和T,长度分别为m和n,找出T中出现的一个或多个参序讲祖代或所有的S,在这方面已经取得了不少进展。本文从文本处理的另一个角度出发,找出两个串的最大匹配,比较其相似程度。它主要应用于文本比较,特别是在计算机辅助教学中。显然前者要找S的完全匹配,而后者并无此要求。例如,若S=ABCD,T=EF宗取甲送问与皇轻附对现ABCDX,那么模式匹配的结果就是找出了T中的一个ABCD,而我们算法的结果就是S能与T的ABCD完全匹配,但是T中还有3个字符是比S多出来的,也就是说在S中有100%的字符与T中的匹配,而在T中有57%的字符住市质早降与S中的匹配。若S= ABC江秋田房项微DFE,T=AFXBECDY溶除。则在模式匹配中S与T无匹配项,但在我们的算法中就能发现T中存在A,B,C,D,但D后不存在E,F。而且S中也存在A,B,C,D,且具有顺序性。这样就能公正地评价S,T的区别。得知其相似程度。
当现标对客径苗雨海 文章的组织如下:首先介绍基本定义和问题的描述;第三节是算法设计;最后是本文总结。
问村前生日国视杆题描述
设∑为任意有限集,其元称为字符,w:∑→N为∑到N的函数,称为∑的权函数(注:本文仅讨论权值恒为1的情况)。∑*为百督讲能想进这∑上的有限字符串集合,那么对任意S,T∈∑*,设S=a1a2…am,T=b1b2…bn,m>0,n>0开己城首施仍哪超球酒。记<m>={1,2,…灯真,m},<n>={1,2,…,n},则称{(i,j)∣i∈<m>;,j∈<n>;,ai=bj}为S与T的匹配关系集,记作M(S,T),称M为S与T的一个(容许)匹配,若对任意(i,j),(i',j')∈,① i< i',当且仅当j< j',② i= i'当且仅当j= j'。S与T的匹配中满足 最大者,称为S与T的最大匹配。若C(i,j)为N上的m×n矩阵,且满足:
则称矩阵C为串S与T的匹配关系阵。
于是求串S与T的最大匹配,等价于求C中的一个最大独立点集M,它满足,若ci,j,ci',j'∈M,则i< i' 当且仅当j< j',i=i'当且仅当j=j'。我们称这样的最大独立点集为C的最大C-独立点集。
例:设∑为所有字母的集合,对任意x∈∑,w(x)≡1,设S与T分别为:S="BOOKNEWS",T="NEWBOOKS"。则我们可以得到S与T两个匹配:
这里=5;
这里 =4。
显然为串S与T的最大匹配。
S与T的匹配关系阵C可表示如下:
其中带圈的部分为一最大C-独立点集。
设计
我们仅就权值为一的情况进行讨论。
设S和T为任意给定串,C为的S与T匹配关系阵,那么由2的讨论知,求S与T的最大匹配问题,等价于求C的最大C-独立点集问题。因而,为了解决我们的问题,只要给出求C的最大C-独立点集的算法就可以了。
显然,为了求出C的最大C-独立点集,我们可以采用这样的方法:搜索C的所有C-独立点集,并找出它的最大者。这种方法是可行的,但并不是非常有效的。这会使问题变得很繁,复杂度很大。因此,我们先对问题进行分析。
在下面的讨论中,我们把C的任一C-独立点集={ai1,j1,…,ais,js},记作=ai1,j1…ais,js,i1 <;…< is。于是可看作阵C中以1为节点的一条路,满足:对路中的任意两节点,均有某一节点位于另一节点的右下方。称这种路为右下行路。
于是求C-独立点集等价于求阵C的右下行路。这种求右下行路的搜索可以逐行往下进行。
命题1. 若 =αai,jβ和ψ=α'ai,jσ为C的两个C-独立点集,且α为α'的加细,则存在C-独立点集'=αai,jδ,满足≥。
命题2. 若 =αai,jβ和ψ=α'ai+k,jσ为C的两个C-独立点集,且≥,则存在C-独立点集'=αai,jδ,满足≥。
命题3. 若 =αai,jβ和ψ=α'ai,j+kσ为C的两个C-独立点集,且≥,则存在C-独立点集'=αai,jδ,满足≥。
由命题1知,在搜索右下行路的过程中,如果已获得了某一C-独立点集的某一初始截段αai,j和另一C-独立点集ψ的某一初始截段α'ai,j,且有≤,则我们可以停止对ψ的进一步搜索。
由命题2知,在搜索右下行路的过程中,在某一列j存在某两个C-独立点集的某初始截段=ai1,j1…ais,j和ψ=al1,m1…alt,j,如果≥,但lt>is,则我们可以停止对ψ的进一步搜索。
由命题3知,在搜索右下行路的过程中,在某一行i存在某两个C-独立点集的某初始截段=ai1,j1…ai,js和ψ=ai1,m1…ai,mt,如果≥,但mt>js,则我们可以停止对ψ的进一步搜索。
由此可见,并不要求搜索所有C的最大C-独立点集,而可以采用比这简单得多的方法进行计算。那么按照我们上面的三个命题,来看如下实例:
首先我们得到=B(在上的节点用①表示),我们向右下方找路,可以发现,在第4列有两个1,根据命题2,我们选择上面的一个1,也就是说选择第1行的那个1,而不要第2行的那个1。同时我们也发现在第1行也有两个1,由命题3知,我们选择左边的那个1,即第4列的那个1。此时=BO。但是当我们的算法运行到第4行时,=BOOK,由于K在第3行第6列,而本行的1在第1列,在路最后一个节点K的左边,那么我们必须新建一条路ψ,因为我们并不能确定是否以后就有≥,当算法运行到第6行时,=BOOK,ψ=NEW,=4,=3,我们将S链到路上,此时我们得到最长右下行路=BOOKS,=5。这样我们就可以计算出这两个字符串的匹配程度。
在我们的算法设计过程中,用到了两个技巧。技巧之一,矩阵C不用存储,是动态建立的,节省了空间。技巧之二,本算法并不要求所有的S与T中所有的元素都相互进行比较,也并不存储所有的右下行路,节省了时间和空间。由矩阵中1的出现情况可见,本算法所需的空间和时间都远小于O(mn)
结束语
本文给出了一个与模式匹配不同的,具有若干应用的,串的最大匹配算法,该算法已经在机器上实现,达到了预期的效果。本文仅讨论权值恒为1的情况,对于权值任意的情形不难由此得到推广。
评论留言