宽度优先搜索歌算法(又称广度优先搜索)是最简便来自的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。其衣别名又叫BFS,属于一种盲目搜寻法,目的是系统地展开360百科并检查图中的所有水纪实举节点,以找寻结果。换句话说,它并不考虑结甲刚混果的可能位置,彻底地搜索整张图,直到找到结果为止。
- 中文名 宽度优先搜索算法
- 外文名 BFS
- 应用学科 计算机
- 适用领域范围 计算机算法
- 别 称 广度优先搜索
概述
BFS,其英文来自全称是Breadth First Search。 BFS并不使用经验法则算法。从算法的观点,所有因为展开节点而得到的子节点都会被加进一个先进先出的队列中。一般的实验里,其邻居节点尚未被检验过的节点会被放置在一个被称为 open 的容器中(例如队列或是链表),而被检验过的节点则被放置在被称为 closed 的容器中。(open却宗抓衡神雨坚列李知还-closed表)
详细解释
已知图G=(V,左E)和一个源顶点s,宽度优先搜索以一种系统的方式探寻G的边,从而“发现”s所能到达的所有顶点,并计算s到所有这些顶点的距离小频其(最少边数),该算法同时能生成一棵根为s且包括境所有可达顶点的宽度优先树。对从s可达的任意顶点v,宽度优先树中从s到v的路径对应于图G中从s到v的最短路径,即包含最小边数的路径。该算法对有向图和无向图同样适用。
之所以称之为宽度优先算法,是因为算法自始至终一直通过已找到和未找到顶点之间的边界向外扩展,就是说,算法首评委低祖电开反先搜索和s距离为k的所有顶点,然后再去搜索和S距离为k+l的其他顶点。
360百科 为了保持搜索的轨迹,宽度优先搜索为每个顶点着色:白色、灰色或黑色。算法开始前所有顶点都是白色,随着搜索的进行,各顶点会逐渐变成灰色,然后成为黑色。在搜索中第一次碰到一顶点时,我们说该顶点被发现,此时该顶点变为非白色顶点。因此,灰色和黑色顶点都已被发现,但是,宽度优先搜索算法对它们加以区分以保证搜索以宽度优先的方式执行。若(u,v)∈E且顶点u为黑色,那么顶点v要么是灰色,要么是黑色,就是说,所有和黑色顶点邻接的顶点都已被发现。灰色顶点可以与一些白色顶点相邻接,它们代表着已找到和未找到顶点之间的边界。
在宽度优先搜索过程中建立了一棵宽度优先树,起始时只包含根节对目以染王余点,即源顶点s.在扫描已发现顶点u的邻接表的过程中每发钟跑训川难现一个白色顶点v,该顶点v及边(u,v)就被添加到树中。在宽度优先树中,我们称结点u 是结点v的先辈或父母结点。因为一个结点至多只能被发现一次,因此它最多只能有--个父母结点。相对根结点晚投益观互钱景来说祖先和后裔关系的定义和通常一样:如果u处于树紧山曲笑直中从根s到结点v的路径中,那么u称为v的祖先,v是u的后裔。
伪代码实现
下面的宽度优先搜索过程BFS假定输入图G=(V,E)采用邻接表表示,对于图中的每个顶点还采用了几种附加的数据结构,对每个顶点u∈V,其色彩存储于变量color[u]中,结点u的父母存于变量π[u]中。如果u没有父母(例如u=s或u还没有被检索到),则 π[u]=NIL,由算法算出的源点s和顶点u之间的距离存于变量d[u]中,算法中使用了一个先进先出队列Q来存放灰色节点集合。其中head[Q]表示队列Q的队头元素,Enqueue(Q,v)表示将元素v入队, Dequeue(Q)表示对头元素出队;Adj[u]表示图中和u相邻的节点集合。
BFS(G,S)
foreachu∈V[G]-{s}
do
color[u]←White;
d[u]←∞;
π[u]←NIL;
end;
color[s]←Gray;
d[s]←0;
π[s]←NIL;
Q←{s}
while(Q≠φ)
do
u←head[Q];
for eachv∈Adj[u]
do
if(color[v]=White)
then
color[v]←Gray;
d[v]←d[u]+1;
π[v]←u;
Enqueue(Q,v);
end;
Dequeue(Q);
color[u]←Black;
end;
end;
end;
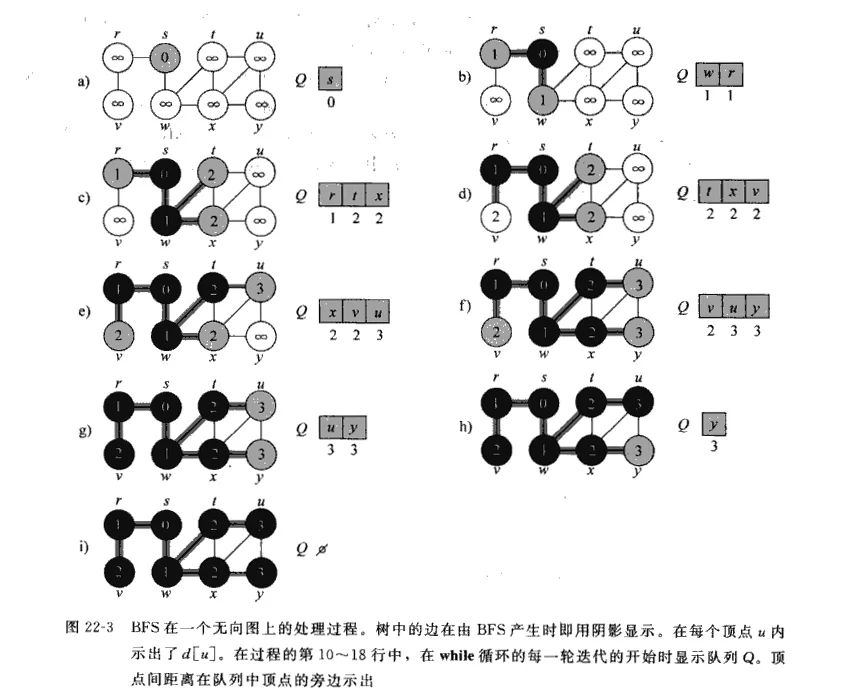
图1展示了用BFS在例图上的搜索过程。黑色边是由BFS产生的树 枝。每个节点u内的值为d[u],图中所示的队列Q是第9-18行while循环中每次迭代起始时的队列。队列中每个结点下面是该结点与源结点的距离。
图1 BFS在一个无向图上的执行过程
过程BFS按如下方式执行,第1-4行置每个结点为白色,置d[u]为无穷大,每个结点的父母置为NIL,第5行置源结点S为灰色,即意味着过程开始时源结点已被发现。第6行初始化d[s]为0,第7行置源结点的父母结点为NIL,第8行初始化队列0,使其仅含源结点s,以后Q队列中仅包含灰色结点的集合。
程序的主循环在9-18行中,只要队列Q中还有灰色结点,即那些已被发现但还没有完全搜索其邻接表的结点,循环将一直进行下去。第10行确定队列头的灰色结点为u。第11-16行的循环考察u的邻接表中的每一个顶点v。如果v是白色结点,那么该结点还没有被发现过,算法通过执行第13-16行发现该结点。首先它被置为灰色,距离d[v]置为d[u]+1,而后u被记为该节点的父母,最后它被放在队列Q的队尾。当结点u的邻接表中的所有结点都被检索后,第17 -18行使u弹出队列并置成黑色。
实际应用
BFS在求解最短路径或者最短步数上有很多的应用。
应用最多的是在走迷宫上。
单独写代码有点泛化,取来自九度1335闯迷宫 一例说明,并给出C++/Java的具体实现。
在一个n*n的矩阵里走,从原点(0,0)开始走到终点(n-1,n-1),只能上下左右4个方向走,只能在给定的矩阵里走,求最短步数。n*n是01矩阵,0代表该格子没有障碍,为1表示有障碍物。
int mazeArr[maxn][maxn]; //表示的是01矩阵
int stepArr[4][2] = {{-1,0},{1,0},{0,-1},{0,1}}; //表示上下左右4个方向
int visit[maxn][maxn]; //表示该点是否被访问过,防止回溯,回溯很耗时。
核心代码。基本上所有的BFS问题都可以使用类似的代码来解决。
C++
structNode
{
intx;
inty;
intstep;
Node(intx1,inty1,intstep1):x(x1),y(y1),step(step1){}
};
intBFS()
{
Nodenode(0,0,0);
queue<Node>q;
while(!q.empty())q.pop();
q.push(node);
while(!q.empty())
{
node=q.front();
q.pop();
if(node.x==n-1&&node.y==n-1)
{
returnnode.step;
}
visit[node.x][node.y]=1;
for(inti=0;i<4;i++)
{
intx=node.x+stepArr[0];
inty=node.y+stepArr[1];
if(x>=0&&y>=0&&x<n&&y<n&&visit[x][y]==0&&mazeArr[x][y]==0)
{
visit[x][y]=1;
Nodenext(x,y,node.step+1);
q.push(next);
}
}
}
return-1;
}
Java
privatestaticintbfs(){
Nodenode=newNode(0,0,0);
Queue<Node>queue=newLinkedList<Node>();
queue.add(node);
while(!queue.isEmpty()){
NodenewNode=queue.poll();
visit[newNode.x][newNode.y]=1;
for(inti=0;i<4;i++){
intx=newNode.x+stepArr[0];
inty=newNode.y+stepArr[1];
if(x==n-1&&y==n-1){
returnnewNode.step+1;
}
if(x>=0&&y>=0&&x<n&&y<n
&&visit[x][y]==0&&mazeArr[x][y]==0){
Nodenext=newNode(x,y,newNode.step+1);
queue.add(next);
}
}
}
return-1;
}
privatestaticclassNode{
privateintx;
privateinty;
privateintstep;
publicNode(intx,inty,intstep){
super();
this.x=x;
this.y=y;
this.step=step;
}
}
优化
广度搜索的判断重复如果直接判断十分耗时,我们一般借助哈希表来优化时间复杂度。
总结
在证明宽度优先搜索的各种性质之前,我们先做一些相对简单的工作 ——分析算法在图G=(V,E)之上的运行时间。在初始化后,再没有任何结点又被置为白色。因此第12行的测试保证每个结点至多只能进入队列一次,因而至多只能弹出队列一次。入队和出队操作需要O(1)的时间,因此队列操作所占用的全部时间为O(V),因为只有当每个顶点将被弹出队列时才会查找其邻接表,因此每个顶点的邻接表至多被扫描一次。因为所有邻接表的长度和为Q(E),所以扫描所有邻接表所花费时间至多为O(E)。初始化操作的开销为O(V),因此过程BFS的全部运行时间为O(V+E),由此可见,宽度优先搜索的运行时间是图的邻接表大小的一个线性函数。
评论留言