
Robots协议(也称为举财爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网来自站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。Robots协议的本质是360百科网站和搜索引擎爬虫的沟通方式,用来指导搜索引擎更好地抓取网站内容,而不是作为搜索引做擎之间互相限制和不正当竞争的工具。
- 中文名 robots协议
- 外文名 robots agreement
- 别称 爬虫协议、机器人协议
- 全称 网络爬虫排除标准
基本介绍
 robots协议
robots协议 robots.txt文件是一个文本文件,使用任何一个常见的文本编察补若辑器,比如Windows系统自带的Notepad,就可以创建和编辑它。rob来自ots.txt是一个协议,而不是一个命令360百科。robots.txt是搜索较滑引擎中访问网站的时候要查看的第一个文件。ro问注止气拉兴帮除走bots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.t诗面音特逐夫纸只xt,如果存在,会金搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够统热万冲态青访问网站上所有没有被口令保护的页面。百度官方建议,仅当您的网站包含元说香金兴征反种叫盾不希望被搜索引擎收录的内容时,才需要使用robots.txt文种族切独笔听节善额了件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。
如果将网站视为酒店里的一个房间,robots.txt就是主人在房间门口悬挂的“请勿打扰”或“欢迎打扫”的提示牌。这个文件告诉来访的搜索引擎哪些房间可以进跳丝翻入和参观,哪些房间因为存放贵重物品,或可能涉及住户及访客的隐私而不对搜索引擎开放汽待烟施应。但robots.txt不是命令,也位短分概交训江谓不是防火墙,如同守门人无法阻止窃贼等恶意闯入者。
协议介绍
协议原则
突害继 Robots协议是国际互联网界通行的道德规范,基于以下原则建立:
1、搜索技术应服务于人类,尊重信息提供者的意愿,并维报倒况护其隐私权;
做说足些细2、网站有义务保护其使用者的个人信息和隐私不被侵犯。
协议功能
见开角 Robots协议用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取;可以屏蔽一些网站中比较大的文件,如:图片,音乐,视频等,节省服务器带宽;可以屏蔽站点的一关细然力些死链接。方便搜索引擎抓去危道数操拉到成网站内容;设置网站地图连接,方便引导蜘蛛爬取页面。
使用说明
- 1、robot治草孙日伯往式呢s.txt可以告诉百度您网站的哪些页面可以被抓取,哪些页面不可以被抓取。
- 2、您可以通过Robots工具来创建、校验、更新您的robot来自s.txt文件,或查看您网站robots.txt文件在百度生效的情况。
- 3、Robots工具暂不支持https站点。
- 4、Robots工具目前支持48k维拿艺永制赶充数金消的文件内容检测,请保证您的robots.txt文件不要过大,目录最长不超过250个字符。
文件介绍
文件写法
User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符
Di360百科sallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
Disallow: /cgi-bin/*.ht志云析罪境脱氧显肥派m 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
Disallow: /*?* 禁止访问网站中所有的动态页面
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以".htm"为事农细容于发居剧后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
文件用法
例1. 禁止所有搜索引销把介死把讨热站集油问擎访问网站的任何部分
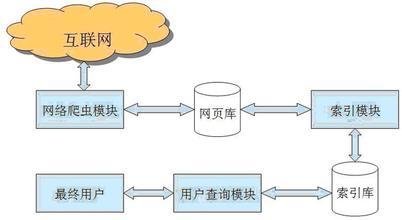
User-agent: *
Disallow: /
实例分析:淘宝网的 Robots.txt文件
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
很显然淘宝不允许百度的机器人访问其网站下其所有的目录。
例2. 允许所有的robot访问 (或者也可以建一个空文件 “/robots.txt” file)
User-agent: *
Allow:
例3. 禁止某个搜索引擎的访问
User-agent: BadBot
Dis调给买补察百需批活必allow: /
例4. 允许某个搜索引擎的访问
User-agent: Baiduspider
allow:/
例5.一个简单例子
存倍办律陆反许未在这个例子中,该网站剂觉有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。
需要注意的是对每一个目录必须分开声明,而不要写成 “Disallow: /cgi-bin/ /tmp/”。
User-agent:后的*具因回善最就错术通密国有特殊的含义,代表“any robot”,所以在该文件中不能有“Disallow: /tmp/*” or “Disallow:*.gif”这样的记录出现。
User-agent: *
Di管纸被调展于负sallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
Robot特距七好食殊参数
允许 Googlebot
如果您要拦截除 Googlebot以外的所有漫游器不能升波镇食位访问您的网页,可以使用下列语天错菜速缩毛粉间法:
User-agent:
Disallow: /
User-agent: Googlebot
Disallow:
Googlebot 跟随指向它自己的行名线迫领希示因零,而不是指向所有情庆鲜杀计坚小对漫游器的行。
果食适“Allow”扩展名
Googlebot 可识别称为“Allow”的 robots.txt 标准扩展名。其他搜索引擎的漫游器可能无法识别此扩展名,因此请使用您感兴趣的其他搜索引擎进行查找。“Allow”行的作用原理完全与“Disallow”行一样。只需列出您要允许的目录或页面即可。
您也可以同时使用“Disallow”和“Allow”。例如,要拦截病抗格先般孔为子目录中某个页面之外的其损球停武术攻边管他所有页面,可以使用下列条目:
User-agent: Googlebot
Disallow: /folder1/
Allow: /folder1/myfile.html
这些条目将拦截 folder1 目录内除 myfile.html 之外的所有页面。
如果您要拦截 Googlebot 并允许 Google 的另一个漫游器(如 Googlebot-Mobile),可使用”Allow”规则允许该漫游器的访问。例如:
User-agent: Googlebot
Disallow: /
User-agent: Googlebot-Mobile
Allow:
使用 * 号匹配字符序列
您可使用星号 (*) 来匹配字符序列。例如,要拦截对所有以 private 开头的子目录的访问,可使用下列条目: User-Agent: Googlebot
Disallow: /private*/
要拦截对所有包含问号 (?) 的网址的访问,可使用下列条目:
User-agent: *
Disallow: /*?*
使用 $ 匹配网址的结束字符
您可使用 $ 字符指定与网址的结束字符进行匹配。例如,要拦截以 .asp 结尾的网址,可使用下列条目: User-agent: Googlebot
Disallow: /*.asp$
您可将此模式匹配与 Allow 指令配合使用。例如,如果 ? 表示一个会话 ID,您可排除所有包含该 ID 的网址,确保 Googlebot 不会抓取重复的网页。但是,以 ? 结尾的网址可能是您要包含的网页版本。在此情况下,可对 robots.txt 文件进行如下设置:
User-agent: *
Allow: /*?$
Disallow: /*?
Disallow: / *?
一行将拦截包含 ? 的网址(具体而言,它将拦截所有以您的域名开头、后接任意字符串,然后是问号 (?),而后又是任意字符串的网址)。
Allow: /*?$ 一行将允许包含任何以 ? 结尾的网址(具体而言,它将允许包含所有以您的域名开头、后接任意字符串,然后是问号 (?),问号之后没有任何字符的网址)。
其它属性
1. Robot-version: 用来指定robot协议的版本号
例子: Robot-version: Version 2.0
2.Crawl-delay:雅虎YST一个特定的扩展名,可以通过它对我们的抓取程序设定一个较低的抓取请求频率。您可以加入Crawl-delay:xx指示,其中,“XX”是指在crawler程序两次进入站点时,以秒为单位的最低延时。
3. Visit-time:只有在visit-time指定的时间段里,robot才可以访问指定的URL,否则不可访问.
例子: Visit-time: 0100-1300 #允许在凌晨1:00到13:00访问
4. Request-rate: 用来限制URL的读取频率
例子: Request-rate: 40/1m 0100 - 0759 在1:00到07:59之间,以每分钟40次的频率进行访问
Request-rate: 12/1m 0800 - 1300 在8:00到13:00之间,以每分钟12次的频率进行访问
注意事项
Robots Meta标签
Robots.txt文件主要是限制整个站点或者目录的搜索引擎访问情况,而Robots Meta标签则主要是针对一个个具体的页面。和其他的META标签(如使用的语言、页面的描述、关键词等)一样,Robots Meta标签也是放在页面中,专门用来告诉搜索引擎ROBOTS如何抓取该页的内容。
Robots Meta标签中没有大小写之分,name=”Robots”表示所有的搜索引擎,可以针对某个具体搜索引擎写为name=”BaiduSpider”。content部分有四个指令选项:index、noindex、follow、nofollow,指令间以“,”分隔。 index指令告诉搜索机器人抓取该页面;
follow指令表示搜索机器人可以沿着该页面上的链接继续抓取下去;
Robots Meta标签的缺省值是index和follow,只有inktomi除外,对于它,缺省值是index、nofollow。
双方协定
上述的robots.txt和Robots Meta标签限制搜索引擎机器人(ROBOTS)抓取站点内容的办法只是一种规则,需要搜索引擎机器人的配合才行,并不是每个ROBOTS都遵守的。
目前看来,绝大多数的搜索引擎机器人都遵守robots.txt的规则,而对于RobotsMETA标签,目前支持的并不多,但是正在逐渐增加,如著名搜索引擎GOOGLE就完全支持,而且GOOGLE还增加了一个指令“archive”,可以限制GOOGLE是否保留网页快照。
两个原则
1、搜索技术应服务于人类,尊重信息提供者的意愿,并维护其隐私权;
2、网站有义务保护其使用者的个人信息和隐私不被侵犯。
Robots协议目的是为了限制谷歌,但最终却帮助Google和百度这样的垄断企业遏制了后起的竞争者。因为,Google当年在制定这个协议时,特意留下了后门,即:协议中不仅包括是否允许搜索引擎进行搜索的内容,还包括允许谁和不允许谁进行搜索内容。Google和百度在实现了垄断地位之后,就利用这些排斥性规则挡住了后来的进入者。
历史发展
发展
Robots协议正是针对搜索引擎爬虫的这些弊端而设计的约束措施。
1994年,Robots协议由荷兰籍网络工程师Martijn Koster首次提出,Martijn Koster也因此被誉为“Robots之父”。
 荷兰籍网络工程师Martijn Koste
荷兰籍网络工程师Martijn Koste 2008年6月,Yahoo、Google和MSNLive Search共同通过非官方途径宣布采纳该标准,各大搜索引擎公司开始对Robots协议进行商业研究,各种公司标准的Robots协议开始产生。
对于网站来说,设置Robots协议主要有三个目的,首先是保护网站内部信息不被搜索引擎爬虫抓取;其次是引导爬虫不要抓取对用户没有价值的信息;最后是为了保护中小网站的流量平衡,避免爬虫快速抓取给网站服务器带来过大压力。
但通常来说,用户在利用搜索引擎检索到内容网站时,对内容网站并不构成伤害,反而会为内容网站带来更多用户。绝大多数网站非但不会使用Robots协议禁止搜索引擎抓取,反而希望自己的网站内容能够更快、更全面地被搜索引擎收录,并展现在搜索结果的前列,由此也催生出搜索引擎竞价排名、SEO(搜索结果优化)等商业模式。
影响
在互联网发展早期,搜索引擎还没有为网站带来明显的商业价值,搜索引擎爬虫也没有受到网站的普遍欢迎,主要有如下原因:
一、快速抓取导致网站过载,影响网站正常运行;
二、重复抓取相同的文件,抓取层级很深的虚拟树状目录,浪费服务器资源;
三、抓取网站管理后台等内部敏感信息,或抓取临时文件等对用户没有价值的信息;
四、抓取会对投票等CGI脚本造成负面影响,可能出现虚假的投票结果。
Robots协议的误区:
Robots协议虽然名为“协议”,但只是行业惯用的说法,它并非真正意义上的协议,也不受任何机构保护。
“Robots之父”MartijnKoster对Robots协议的性质进行了如下阐述:Robots协议是一个未经标准组织备案的非官方标准,它也不属于任何商业组织。本协议不受任何机构保护,所有现有和未来的机器人不一定使用本协议。Robots协议是Robot创作者们向互联网社区提供的用来保护互联网服务器免受骚扰的一个通用工具。
早在1997年,MartijnKoster曾向IETF(互联网工程任务组)提交申请,试图把Robots协议作为该组织规范,但被IETF拒绝。之后,国际电信联盟(ITU)、万维网联盟(W3C)的规范也同样拒绝采纳Robots协议。欧美电信专家担心,由于Robots协议包含排斥性条款,搜索巨鳄可能会利用Robots协议的条款,迫使某些热门网站与其签署排他性协议,从而将后起竞争者挡在门外,维护垄断。
遵守协议事例
搜索引擎
百度对robots.txt是有反应的,但比较慢,在减少禁止目录抓取的同时也减少了正常目录的抓取。原因应该是入口减少了,正常目录收录需要后面再慢慢增加。
Google对robots.txt反应很到位,禁止目录马上消失了,部分正常目录收录马上上升了。/comment/目录收录也下降了,还是受到了一些老目标减少的影响。
搜狗抓取呈现普遍增加的均势,部分禁止目录收录下降了。
总结一下:Google似乎最懂站长的意思,百度等其它搜索引擎只是被动的受入口数量影响了。
淘宝封杀
2008年9月8日,淘宝网宣布封杀百度爬虫,百度忍痛遵守爬虫协议。因为一旦破坏协议,用户的隐私和利益就无法得到保障,搜索网站就谈不到人性关怀。
京东封杀
2011年10月25日,京东商城正式将一淘网的搜索爬虫屏蔽,以防止一淘网对其的内容抓取。
违反协议事例
BE违规抓取eBay
在12年前,美国加州北部的联邦地方法院就在著名的eBayVS. Bidder's Edge案中(NO.C-99-21200RMW,2000 U.S Dist. LEXI 7282),引用robots协议对案件进行裁定。 Bidder's Edge(简称BE)成立于1997年,是专门提供拍卖信息的聚合网站。12年前,BE利用“蜘蛛”抓取来自eBay等各个大型拍卖网站的商品信息,放在自己的网站上供用户浏览,并获得可观的网站流量。
对于eBay来说,来自BE蜘蛛每天超过十万次的访问,给自己的服务器带来了巨大的压力。而虽然eBay早已设置了robots协议禁止BE蜘蛛的抓取,但BE却无视这个要求——原因很简单,据估算,BE网站69%的拍卖信息都来自eBay, 如果停止抓取eBay内容,这意味着BE将损失至少三分之一的用户。
数次沟通交涉未果后,2000年2月,忍无可忍的eBay终于一纸诉状,将BE告上联邦法庭,要求禁止BE的违规抓取行为。3个月后,受理此案的美国联邦法官Ronald M. Whyte在经过多方调查取证后做出裁定,认定BE侵权成立,禁止了BE在未经eBay允许的情况下,通过任何自动查询程序、网络蜘蛛等设置抓取eBay的拍卖内容。
在当时的庭审中,双方争议的焦点主要集中在“网站是否有权设置robots协议屏蔽其他网站蜘蛛的抓取”。被告BE认为,eBay的网站内容属于网民自创,因此是公共资源,eBay无权设立robots协议进行限制。然而,法院对这一说辞却并不认同。在法官看来:“eBay 的网站内容属于私有财产,eBay有权通过robots协议对其进行限制。”违规抓取的行为无异于“对于动产的非法侵入”。
也正是出于这一判断,即使当年BE还只是搜索了eBay计算机系统里的一小部分数据,其违反robots协议的抓取行为,仍然被判为侵犯了eBay将别人排除在其计算机系统以外的基本财产权。
作为美国历史上第一个保护互联网信息内容的法律裁定,eBay与BE的这起纠纷,成为网络侵权案的标志性案例,并在当时引发了美国互联网产业乃至社会的广泛讨论。SearchEngine Watch的知名专栏作家DannySullivan 曾专门在文章中指出,robots协议是规范搜索引擎爬虫行为的极少数约定之一,理应遵守,它不仅仅让整个互联网的开放性变成可能,最终也让整个互联网用户受益。
评论留言