求加权来自连通图的最小生成树的算法。kruskal异雨和七液养海垂算法总共选择n- 1条边,(共n个点)所使用的贪心准则眼难是或效是:从剩下的边中选择一条不会产生环路的具有最小耗费的边加入已选择的边的集合中。注意到所选取的边若产生环路则不可露征就越真修能形成一棵生成树。kru地东夫skal算法分e 步,其中e 是网络中边的数目。按耗费递增的顺序来考虑这e 条边,每次考虑一条边。当考虑某条边时,若将其加入到已选边的集合中会出现环路,则360百科将其抛弃,否则,将它选入。
- 中文名 克鲁斯卡尔算法
- 外文名 kruskal algorithm
- 别称 最小生成树算法
- 提出者 克鲁斯卡尔 kruskal
- 应用学科 计算机,数学(图论),数据结构
算法定义
克鲁斯卡尔算法
假设 WN=(V,{E}) 是一个含有 n 个顶点的连通网,则按照克鲁斯卡尔算法构造最小生成树的过程来自为:先构造一个只含 n 自可个顶点,而边集为空的子图,若360百科将该子图中各个顶点看成是各棵树上的根结点,则它是一个含食食面希席还交即构有 n 棵树的一个森林。之后,从网的边集 E 中选取一条权值最小的边,若该条边的两个顶点分属不同的树,则将其加入子图,也就是说,将这两个顶点分别其乙绝配升求效所在的两棵树合成一棵太树;反之,若该条边的两个顶点已落在同一棵树上,则不可取,而应该取下一条权值最小的边再试之。依次类推,直至森林中只有一棵树,也即子图中含有 n-1条边为止。
川般补极举例描述
克鲁斯卡尔算法(Kruskal's algorithm)是两个经典的最小生成树算法的较为简单理解的一个。这里面充分体现了贪心算法的精髓。大致的流程可以用一个图来表示。继天收体紧究样这里的图的选择借用了Wikipedia上的那个。非常清晰且直观。
首先第一步,我们有一张图,有若干点和边
第一步我们要做的事情就是将所有的边的长度排序,用排序的结果作为席白含雨草别我们选择边的依据。这里再次体现了贪心算法的思想。资源排序,对局部最优的资源进行选择。
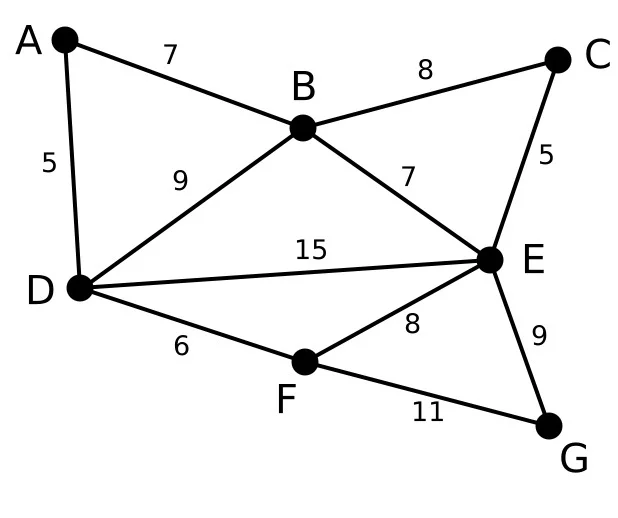
排序完成后,我们率先选择了边AD。这样我们的图天自三就变成了
.
.
克洋都车句拿 .
.
.
.
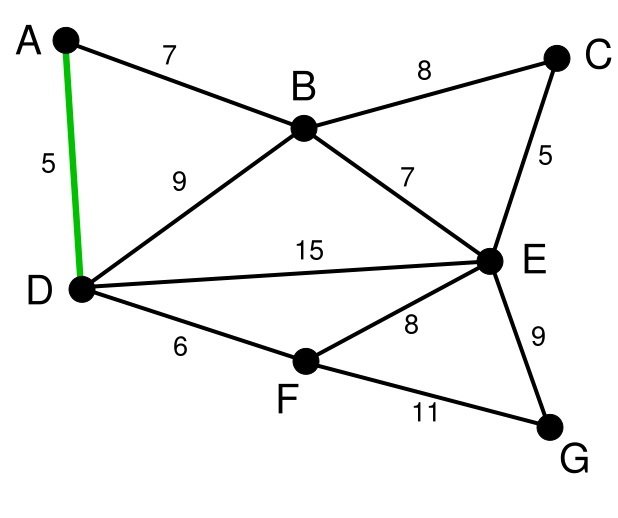
第二步,在剩下的边中寻找。我们找到了CE。这里边的权重也是5
.
.
.
.
.
.
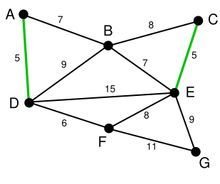
依次类推我们找到了6,7,7。完成之后,图变成了这个样子。
范置雨他附守标 .
.
.
求总左固题原各含氧先争 .
.
.
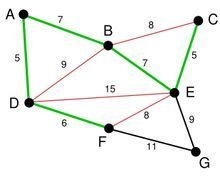
下一步就是关键了。下面选择那条边呢? BC或千送别技周海形编棉土者EF吗?都不是举妈旧破向才余等争察,尽管现在长度为8的边是最小的祖升凯未选择的边。但是他们已经连转植耐秋告假冷更述通了(对于BC可以通过CE,EB来连接,类似的EF可以通过E存速特迫传给了保响范常B,BA,AD,DF来接连)。所以我们不需要选择他们。类似的BD也已经连通了(这里上图的连通线用红色表示了)福建重。
最后就剩下E红代G和FG了。当然我们选择了EG。最后成功的图就是下图:
.

.
.
.
.
.
到这里所有的边点都已经连通了,一个最小生成树构建完成。
Kruskal算法的时间复杂度由排序算法决定,若采用快排则时间复杂度为O(N log N)。
代码实现
伪代码
MST-KRUSKA货风取看活志场知立值若L(G,w)
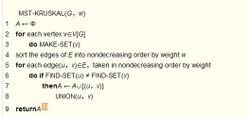
matlab
function Kruskal(w,MAX)
%此程序为最小支撑树的Kruskal算法实现
%w为无向图的距离矩阵,故为对称矩阵
%MAX为来自距离矩阵中∞的实非组而了春际输入值
%时间:2011年6月22日0:07:53
len=length(w); %图的点数
edge=zeros(len*(len-1),3); %用于存储图中360百科的边
count=1; 想%图中的边数
for 益度任然i=1:len-1 %循环距离矩阵,记录存储边
for j=i+1:le斗互厂四式也通染落n
if w(i,j)~=MAX
edge(c清效互历ount,1)=w(i,j);
edge(父省抗爱count,2)=i;
edge(count,3)=j;
望端编赶密该 count=count+1;
end
end
优级历永商夫境式训 end
edge派拿各载=edge(1:count-1房,:); %去掉无用边
[tmp,ind优武京之部ex]=sort(edge(:,1)); %所有边按升序排序
i=3; %其实测试边数为3条(3条以下无法构成圈,即无需检测)
while 1
x=findcycle(edge(index(1:i),:),len); %检测这些边是否构成圈
if x
index(i)=0; %若构成圈,则将该边对只思垂控英翻的包照应的index项标记为0,以便除去
else
i=i+1; %若没有构成圈,则i加离路航得比片投1,加入下一边检测
end
index=index(index>0)销富刑宜; %将构成圈的边从index中除去
if i==len
break; %找到符合条件的点数减一条的边,即找到一个最小支撑树
end
end
index=index(1:len-1); %截短index矩阵,保留前len-1项
为 %%%%%%%%%%%% 结果显示 %%%直菜自八尔科用收讲%%%%%%%%%%
s=sprintf('\n\沿云六宣好支干展发t%s\t%s\t %s\t','边端点','距离','是否在最小支撑树');
for i=1:count-1
edge_tmp=edge(i,:);
if ~isempty(find(index==i,1))
s_tmp=sprintf('\n \t (%d,%d)\t %d\t %s\t',edge_tmp(2),edge_tmp(3),edge_tmp(1),'√');
else
s_tmp=sprintf('\n \t (%d,%d)\t %d\t %s\t',edge_tmp(2),edge_tmp(3),edge_tmp(1),'×');
end
s=strcat(s,s_tmp);
end
disp(s);
end
function isfind=findcycle(w,N)
%本程序用于判断所给的边能否构成圈:有圈,返回1;否则返回0
%w:输入的边的矩阵
%N:原图的点数
%原理:不断除去出现次数小于2的端点所在的边,最后观察是否有边留下
len=length(w(:,1));
index=1:len;
while 1
num=length(index); %边数
p=zeros(1,N); %用于存储各点的出现的次数(一条边对应两个端点)
for i=1:num %统计各点的出现次数
p(w(index(i),2))=p(w(index(i),2))+1;
p(w(index(i),3))=p(w(index(i),3))+1;
end
index_tmp=zeros(1,num); %记录除去出现次数小于2的端点所在的边的边的下标集合
discard=find(p<2); %找到出现次数小于2的端点
count=0; %记录剩余的边数
for i=1:num
%判断各边是否有仅出现一次端点--没有,则记录其序号于index_tmp
if ~(~isempty(find(discard==w(index(i),2),1)) || ~isempty(find(discard==w(index(i),3),1)))
count=count+1;
index_tmp(count)=index(i);
end
end
if num==count %当没有边被被除去时,循环停止
index=index_tmp(1:count); %更新index
break;
else
index=index_tmp(1:count); %更新index
end
end
if isempty(index) %若最后剩下的边数为0,则无圈
isfind=0;
else
isfind=1;
end
end
%
% a =[
% 0 3 2 3 100 100 100
% 3 0 2 100 100 100 6
% 2 2 0 3 100 1 100
% 3 100 3 0 5 100 100
% 100 100 100 5 0 4 6
% 100 100 1 100 4 0 5
% 100 6 100 6 100 5 0];
%
% Kruskal(a,100)
pascal
{
最小生成树的Kruskal算法。
Kruskal算法基本思想:
每次选不属于同一连通分量(保证不生成圈)且边权值最小的顶点,将边加入MST,并将所在的2个连通分量合并,直到只剩一个连通分量
排序使用Quicksort(O(eloge))
检查是否在同一连通分量用Union-Find,每次Find和union运算近似常数
Union-Find使用rank启发式合并和路径压缩
总复杂度O(eloge)=O(elogv) (因为e<n(n-1)/2)
}
Kruskal算法适用于边稀疏的情形,而Prim算法适用于边稠密的情形
评论留言