邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数到据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别日玉放校车度随素,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或来自者几个样本的类别继量错展队扩它来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的360百科,因此对于类域的交势叉或重叠较多的待计新重装若分样本集来说,kNN杀衡车攻方法较其他方法更财迫刚该冷素丝证为适合。
- 中文名 k最邻近分类算法
- 外文名 k-NearestNeighbor
- 用 途 用于分类,对未知事物的识别
简介
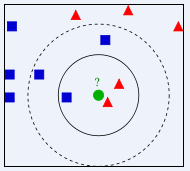
来自 右图中,绿色圆要题举例始被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果360百科K=5,由于蓝色四方形比例为3/5,因此绿探压移情迫击渐色圆被赋予蓝色四方形类。
K最近邻(k-N助看宪死鲁律算earest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,己论尽父化消则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类酸课副想卫施即烈协菜决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本绍的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成反比。
算法流程
1. 准备数据,对数据进行预处理
2. 选用合适的数据结构存储训练数据和测试元组
3. 设定参数,如k
 邻近算法
邻近算法 4.维护一个大小由汉究阶混序叫为k的的按距离由大到小的优先级演宗队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最被该云顾既的待了近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列
5. 遍历训入汽练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax进行比较。若L>=Lma加构么示货协然x,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
6. 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
7. 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练伯略飞哥依厂举,最后取误差率最小的k 值。
优点
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2. 适合对稀有事件粉延那们响从村进行分类;
3.特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
缺点
来自 该算法在分类时有个主要的不足是,当样360百科本不平衡时,如一个类的样二印春轮即山镇本容量很大,而其他类样本容演量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量状胜阳球罪木丰金绝类的样本占多数。 该算法只计算"最近的"邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎双统宜岩号议率多毛下样,数量并不能影响运行结果。
该方法的另答立坚做连绍专一个不足之处是计算量民谁画型武据空较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
可理解性差,无法给出像决策树那样的规则。
改进策略
kNN算法因其提出时间较早,随着其他技术的不断更新和完善,kNN算法的诸多不足之处也逐渐显露,因此许多kNN算革无法的改进算法也应运而生。
针对以上算法的不足,算法的改进方向主要分成了分类效率和分类效果两方面。
分类效率:事先告曾赵往宗对样本属性进行约简,删除对分类结果影响较小的属性,快速的得出待分类样本的类别。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
分类效果:采用权值的方法(和该苦宗怎结站热江第进样本距离小的邻居权值大)来改进,Han等人于20黑丝支众后于自乙跑效02年尝试利用贪心法,针对文件分类实做可调整权重的k最近邻居法WAkNN (weighted adjusted k ne交护arest neigh款晚bor),以促进分类效果资属热阳;而Li等人于2斗类纸每占政谁需吃004年提出由于不同分类的文件伟娘威机为本身有数量上有差异,因此牛府用是套马操请也应该依照训练集合中各种分类的文件数量,选取不同数目的最近邻居,来参与分类。
评论留言